With the recently released version 5.1, Gradle has added a great, subtle new feature that lets you specify which dependencies should be pulled from which repositories. To explain what this is, let’s start with the default behavior. In your Gradle file, you probably have multiple repositories defined, like this:
 When Gradle needs to find a dependency, it will search each of those repositories, in the order they are declared. So when it goes to download, for example, [com.android.support.constraint:constraint-layout:1.1.3], it will first check the Google repo, which has that artifact, so it’s done. But then let’s say you want RxJava: [io.reactivex.rxjava2:rxjava:2.1.9]. Gradle checks for it in the Google repo, but Google responds with a HTTP 404 error, so Gradle moves on to the next repository, which is JCenter. And on and on, for each dependency in your build.
When Gradle needs to find a dependency, it will search each of those repositories, in the order they are declared. So when it goes to download, for example, [com.android.support.constraint:constraint-layout:1.1.3], it will first check the Google repo, which has that artifact, so it’s done. But then let’s say you want RxJava: [io.reactivex.rxjava2:rxjava:2.1.9]. Gradle checks for it in the Google repo, but Google responds with a HTTP 404 error, so Gradle moves on to the next repository, which is JCenter. And on and on, for each dependency in your build.
This can lead to a couple of problems:
- There’s a performance problem. Since you have to check each repository in order for each dependency, there are a lot of requests that return a 404, and you waste time and resources. Wouldn’t it be nice if we could tell Gradle “oh, I know RxJava is on JCenter, so don’t bother checking the Google repository”?
- If a repository that’s first in the list gives a bad response (like the time JCenter responded to Google artifacts with an HTTP 409 error). Gradle will give up, and not check other repositories. This will break your build, and leads to a lot of advice like “make sure you list the Google repository first!”
- You’re vulnerable to a spoofing attack. If you have a dependency that’s in your last repository (fabric in the example above), but a malicious actor uploads a library with the same group and artifact names to JCenter, for example, Gradle will download the JAR from JCenter since it’s higher in the list, and you’ll never know the difference. JCenter doesn’t do much to verify that you are who you say you are, so this type of attack is a real risk.
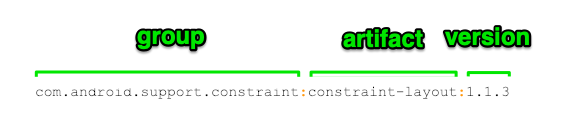
So how do we resolve this? Gradle 5.1 adds a new API so you can specify which groups to include or exclude in a repository. A quick note about what I mean by groups: it’s the bit before the first colon in a Gradle coordinate.
So in practice, your build.gradle might now look something like this – note that you can match groups exactly or with a regular expression:
Now, when Gradle goes to download constraint layout, it will match the regex on the google repo, and Gradle will never attempt to download it from another repository. Likewise, even though the Google maven repository is listed first, Gradle won’t attempt to download RxJava from it, because it’s not listed in the include groups.
If you want to test this, try running a Gradle task with “–refresh-dependencies”, which will force Gradle to try to download all of your dependencies again. If you get an error like this one then you know you still need to work on your configuration.
> Could not resolve all files for configuration ':app:debugCompileClasspath'.
> Could not find io.reactivex.rxjava2:rxjava:2.2.2.
The important thing to know about includes and excludes is that the behavior is defined per repository.
- If you list an include – Gradle will only try to download the included groups for this repository.
- If you list an exclude – Gradle will try any groups except the excluded groups for this repository.
- If you list includes and excludes – Gradle will download only groups that are included and not excluded.
There’s one non-obvious thing that I want to really emphasize, though: If you specify includeGroups on repo but don’t specify any groups on a second repo, like the screenshot below, Gradle will still try to download com.google artifacts from both of these repositories. The options you declare for one repository don’t affect other repositories.

This leads to my last, but perhaps most important piece of advice: whitelist every group. The best way I can see to use this is to include every group in the appropriate repository, and make sure every listed repository has an includeGroup declared. This will force Gradle to download each dependency from the right repository only.