I live in North Carolina, where you have three options for voting:
- “Early Voting” – several sites around the county that are open for ~10 days before Election Day.
- Mail-in absentee – you request that a ballot be mailed to you, you fill it in by hand, and mail it in.
- Election Day – you show up at the precinct in your neighborhood and cast your vote on the day of the election.
I wanted to see what the breakdown is between those three voting methods, and how that has changed over time, so I looked at the data for the last four presidential elections*.
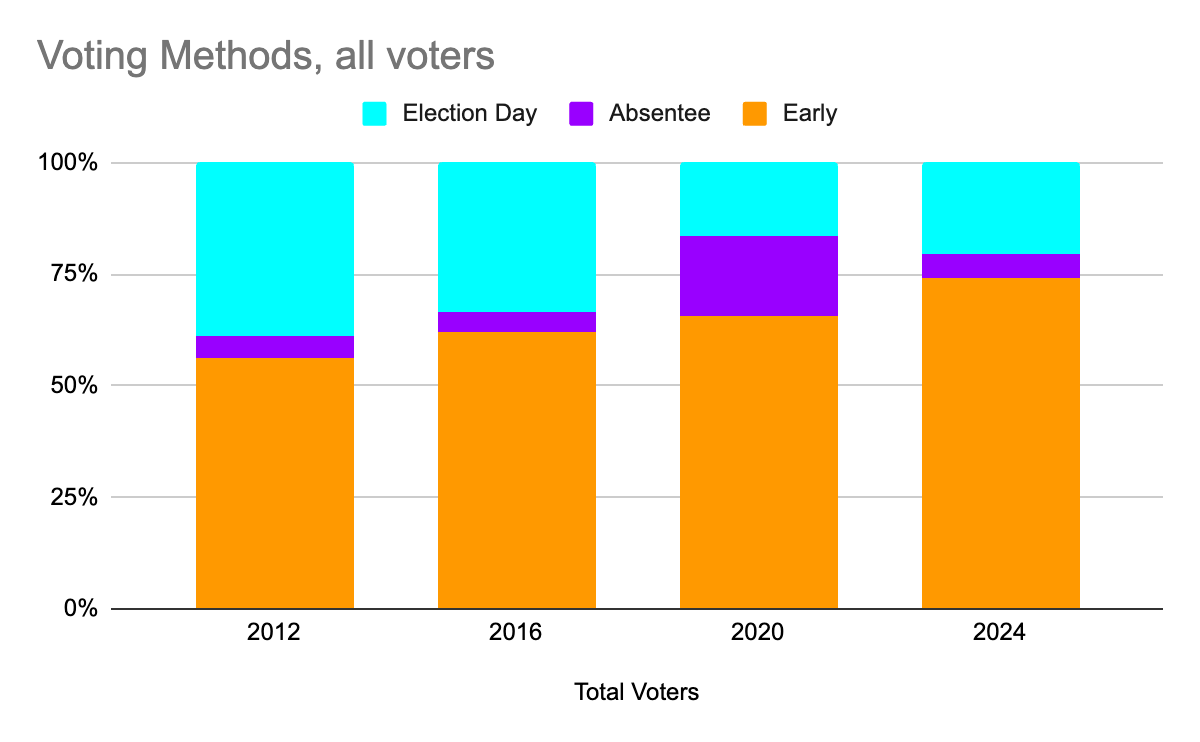
Early voting is popular, and becoming even more popular — 74.2% of voters used early voting in the 2024 election.
Note, of course, that 2020 is an outlier — more voters used mail-in absentee voting to avoid human contact during the COVID-19 pandemic.
I also wanted to see if there was a difference between the two major parties, whether voters of one party were more likely to use one voting method or another. It turns out that there is a difference, but it’s small, and shrinking over time. (Sorry for the wall of numbers — I tried putting this one into a chart, too, but the difference are so small that it’s hard to read.)

Here’s what I read from this one — in the past, there was a clear difference in voting methods, with Early Voting being more popular among Democratic voters, and Election Day Voting being more popular among Republican voters, but those numbers weren’t terribly big, and they have shrunk considerably. To the point where Early Voting was within 1%, and Election Day voting was down to a 4% difference.
* Presidential Elections to get consistency — turnout varies a lot depending on which races are on the ballot — Presidential Elections get the highest turnout, and municipal elections are the lowest. Not only the total turnout, but the breakdown between the voting methods changes a lot. Sticking with one election type gets more consistent numbers that are easier to learn from.
** “GOP Voters” here is a shorthand meaning “ballots cast for the GOP candidate for president” — it doesn’t correlate to the voter’s party registration, or their votes in other races on the ballot.