I think it’s important for any app that deals with sensitive user data to incorporate code obfuscation into their security. While far from impenetrable, it’s a useful layer in thwarting reverse-engineers from understanding your app and using that knowledge against you. If you’ve wondered why I seem to be on a code obfuscation kick recently, it’s because I’ve noticed, anecdotally, that a lot of apps I expected to be using obfuscation, weren’t. So I set out to see if I could do some research and turn that anecdote into data.
I took all of the apps I have on my phone right now, and calculated how well the code was obfuscated (see methodology notes at the end of the post if you’re curious). Here are the points that jumped out at me:

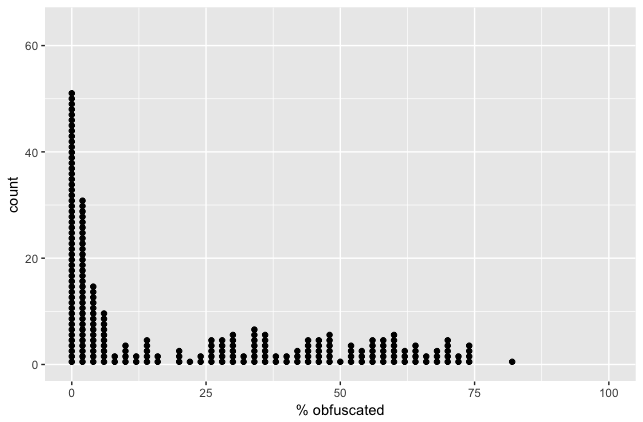
- Most of the apps on my phone aren’t obfuscated. 53% of apps fall in the 0-20% obfuscated bucket, which means they probably didn’t have ProGuard turned on at all.
- Most of the remaining apps are poorly-to-medium obfuscated. The next 35% of apps are 20-60% obfuscated, which means they probably put some effort into obfuscating the code, but weak configurations (like overusing the -keep directive) have kept much of their code un-obfuscated.
- A small portion of apps are well obfuscated. Just 12% of apps are in the 60+% obfuscated range, where most of their code is very difficult to follow.
Why would an app with ProGuard turned off have a score greater than 0? A small part of that would be due to false positives (see the “Methodology” section, below) but most is due to third-party library code that has its internal implementation details obfuscated, before that code is even packaged into an app.
Methodology
-
- Corpus – As alluded to in the post, I ran this analysis on the apps that I have installed on my personal phone. This group of apps probably isn’t a perfectly representative sample of apps on the app store. It is, however, a representative sample of apps that I actually care about 🙂
- Tools – to calculate the “% obfuscated” metric, I used the `apkanalyzer` tool included in the Android SDK. Looking through the classes, methods, and fields, I counted the number that appear to have been obfuscated (see next point), and added them all up for a ratio.
- Metric – deciding whether something has been obfuscated isn’t straightforward; different obfuscation methods will yield different results. But I know ProGuard is a common tool for Android obfuscation, and it prefers to transform names to single-character names, so I checked for single-character names. This has the potential for false positives (e.g. x, y, z in a graphics data class would register as obfuscated even though those are probably the original names) and false negatives (any other obfuscation method might choose different names which aren’t single-character, which this analysis would miss).