I got the chance to talk about what’s new in Android P at the I/O Extended event put on by GDG Charlotte.
If you want to learn more, check out:
Android development, mostly
I got the chance to talk about what’s new in Android P at the I/O Extended event put on by GDG Charlotte.
If you want to learn more, check out:
I’ve written several blog posts recently about technical aspects of using ProGuard to obfuscate your code in Android apps. Then, in March, I gave a talk at DroidCon Boston walking through an overview of How ProGuard Works. Through all of those, I tried to keep the content very matter-of-fact and technical. I got a lot of technical questions in response, but I also got a lot of questions about the organizational and software engineering aspects — how to think about maintenance, and testing, and debugging, and communicating with your team. So what follows are the less technical, but possibly more practical, guidelines I’ve found for working with ProGuard.
You’ll find that most of these tips are focused on the fact that obfuscation can expose problems that are only seen at runtime, and then only when a specific code path is executed. This means that most of these rules are focused on making sure you’re likely to discover those problems.
If possible, start using ProGuard from day 1 of a new project. I’ve gone through the experience of enabling ProGuard on a project that’s been worked on for years without it, and it’s more difficult. You’ll get a warning about some code, and you’ll find that nobody on the team remembers that code.

Enabling ProGuard from day 1 ensures that issues are encountered immediately, when the relevant code is fresh in your mind.
Don’t enable ProGuard in your day-to-day dev builds*, it will increase your build times a little and cause you extra pain in debugging. But for every other build — QA, beta, release — turn ProGuard on. You want as many testers as possible exercising the code as many ways as possible to ensure that you notice any ProGuard bugs early on.
*There is an exception to this, which is when you get a report of a bug that you suspect might be triggered by obfuscation, you want to enable ProGuard in your dev environment so you can easily reproduce the bug. This means that you want to have a single, easy, flag in your build.gradle that you can flip to true to enable ProGuard on your debug builds. Have all of the configuration files ready for that build type — the same configuration files you’re using for the rest of your builds — you want the only effort on your part to be flipping the one flag.
If you’ve inherited a codebase that is already in production, you can’t enable ProGuard from day 1, but you can try to fake it a bit. Start by enabling ProGuard in your dev builds and fixing the compile-time errors. Then, run a ProGuard-ed build and exercise the app as much as possible. Walk through each feature as well as you can, and try to find problems. Next, enable ProGuard for your QA builds, and wait for a bit. This is the real key.
You’ll give your QA team time to work through the app and find problems. You want to make sure they’ve had time to exercise the app before you move on to the next phase, which is a beta build, if you have one. A beta should hopefully expose your obfuscated app to a broad, but still small, set of users. Let that work for a bit, then you can enable for your public builds.
I’ve mentioned this in my blog post and in the talk, but it bears repeating. There’s no value in using ProGuard if you’re going to kneecap it with overly-broad keep rules.
This is deceptively important. It’s tempting to just add the keep rule you need to a config file and be done, but you’re hurting yourself in the long run. A year from now, you’ll look at the rule and wonder why it was there. It might be referring to code that’s long gone, or a library that’s no longer used. Or it could be critically important. You don’t know, because the rule itself doesn’t tell you the reason it was added. And, perhaps more importantly, it doesn’t tell you how to test whether it’s still necessary.
Add a comment. Explain what was broken and why that rule fixed it.
That’s it. Try it out. If you’ve got some different ideas, based on your experience, I would love to hear it.
Thanks for watching my talk, How ProGuard Works, at Droidcon Boston or Android Summit. Here are some of the links that I mentioned in my slides, as well as links to some of my blog posts including the diagrams I used.
R8:
My posts:
Gradle snippet for forcing a particular version of ProGuard:
buildscript { ... configurations.all { resolutionStrategy { force 'net.sf.proguard:proguard-base:6.0.1' } } }
When ProGuard runs on your Android app, it’s not only using the rules that you’ve explicitly added, but rules from a couple of other sources as well. Below are four sources to watch out for:
These are the rules in a file that you add with `proguardFile` in your build.gradle. If you’ve used ProGuard at all, you’re probably accustomed to adding configuration rules here.

A base set of widely-applicable rules get added by that “getDefaultProguardFile” line above, which you’ll see in the template build.gradle file. It protects things like Parcelables, view getters and setters (to enable animations on view properties) and anything with the @Keep annotation. You should walk through this file to see what ProGuard rules get added by default. It’s also a great source of example rules when you’re trying to make your own.

When AAPT processes the resources in your app, it generates rules to protect, for example, View classes that are referenced from layout files, and Activities referenced in your manifest. Each rule comes with one or more comments saying where the class was referenced, so you can track down the offending resource if need be. You can find these rules in:
build/intermediates/proguard-rules/{buildType}/aapt_rules.txt.

Note that this source isn’t explicitly added in your build.gradle, the Android Gradle Plugin takes care of including these rules for you.
If an Android library has ProGuard configs that apps should use when they include that library, the library can declare those rules with the consumerProguardFile method in its build.gradle. For example, here’s a snippet from Butterknife’s build.gradle.

Rather than trying to track down every single source of ProGuard config that’s getting added to your app, you can look at them all together. You can specify
-printconfiguration proguard-config.txt
in your rules file and ProGuard will print out all of the configuration rules to the specified file. Note that they’re not in the same order that they were originally specified, so it can be hard to figure out where a particular rule is coming from.
When ProGuard processes an Android app, it generates a few output files to show what happened in each step. These files can be really helpful if you’re trying to figure out what ProGuard changed, or why your code ended up the way it did. But those files aren’t self-documenting, so I’m going to walk you through why each of those files is created and what it shows you.
These files are in the build directory, something like:
app/build/outputs/mapping/{buildType}/
Here’s a diagram I made with a really high-level overview of the steps ProGuard takes when it’s analyzing your app, because the output files line up nicely with these steps. Refer back to this for some context around the following steps.
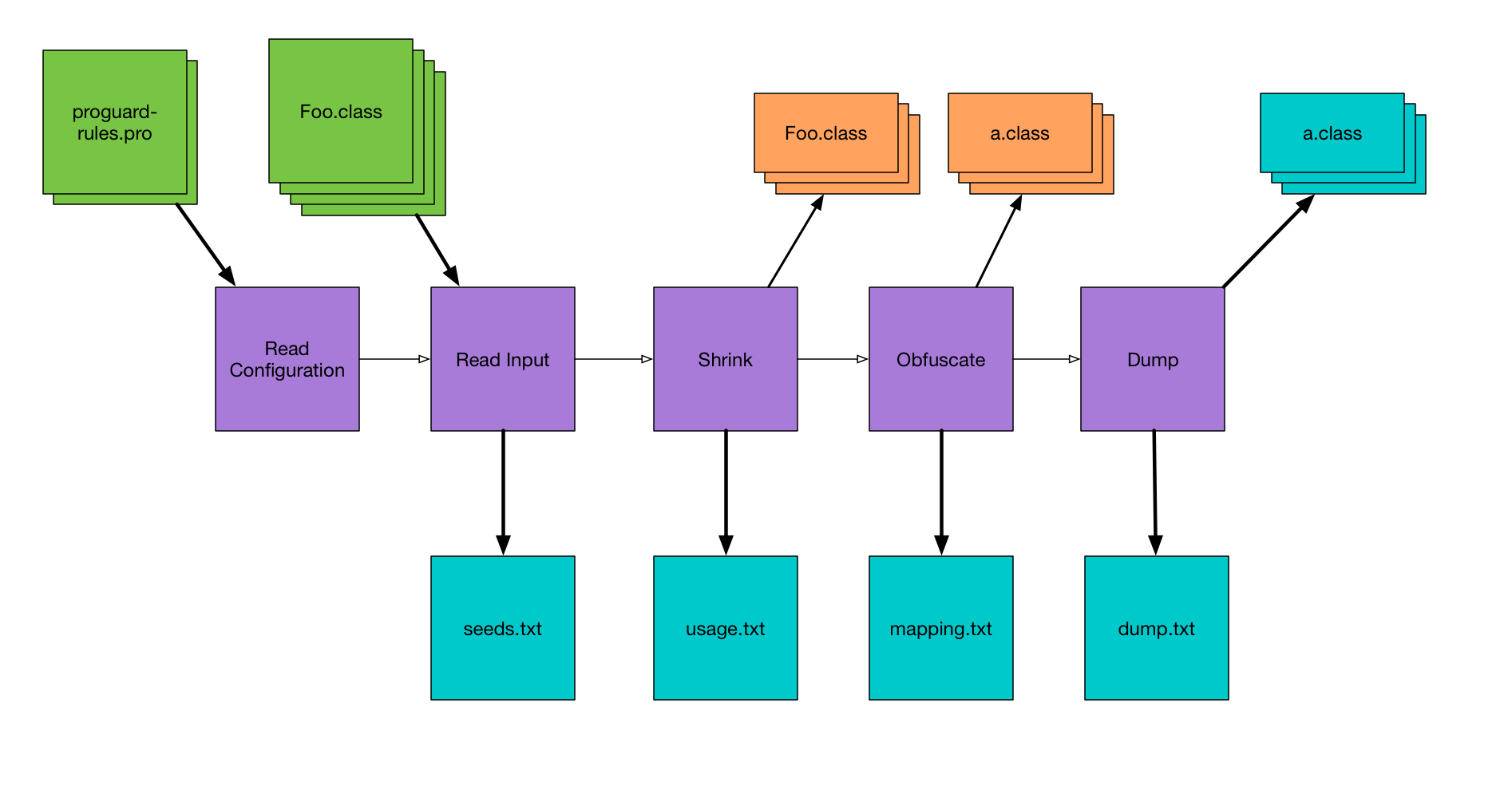
The first things ProGuard does is to read all of your configuration files, and then read in all of the Java bytecode (.class files) to create what it calls the class pool. ProGuard then looks through the class pool and prints to seeds.txt a list of every class and member that matches any of your keep rules. This is useful for debugging if the keep rule you wrote actually matches the class you’re trying to keep.

If it’s a class that matches, there will be a line with just the fully-qualified name of the class. For a member, it will be the fully-qualified class name, followed by a colon, followed by the member’s signature.
Knowing what code it has to keep, ProGuard then goes through the class pool and finds code that it doesn’t need to keep. This is the shrinking phase, where ProGuard strips out unused code from the app. As it’s doing this, it prints out unused code — code that’s being removed — to usage.txt. Now this name seems backwards to me; I think it should be unused.txt or shrinkage.txt or something, but that’s just me.
This is useful if you’re trying to figure out why a class doesn’t exist at runtime. You can check whether it got removed here, or got renamed in the next step.

If an entire class is removed, you’ll get a line with the fully-qualified class name. If only certain members of a class are removed, you get the class name followed by a colon, and then a line (indented with four spaces) for each member that was removed.
The next thing ProGuard needs to do is obfuscate as much code as possible — that is, it’s going to rename classes and members to meaningless names like “a”, “b”, etc. As it’s doing this, ProGuard prints the old name and new name for every class and member to mapping.txt. Not all code is renamed, but all code is listed in mapping.txt.
This is the file you need if you’re trying to de-obfuscate a stacktrace. It allows you to work backwards from the obfuscated names to the original names of code.
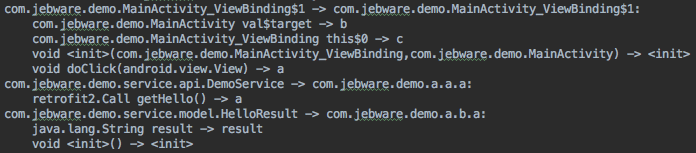
Each line is of the form “{old name} -> {new name}”. You get a line for the class name, then a line for each member of the class. Note that constructors are shown as “<init>()”.
After ProGuard has done all of its magic (shrinking and obfuscating), it prints out one last file which is essentially a full listing of all the code after processing. That is, everything that’s left in the class files, but in a less optimized format, so it’s a huge file. I have a demo app that I use for testing ProGuard stuff, and the final app is about 1 MB, but the dump.txt is almost 18 MB. It’s enormous. Here’s the output for a trivial class:
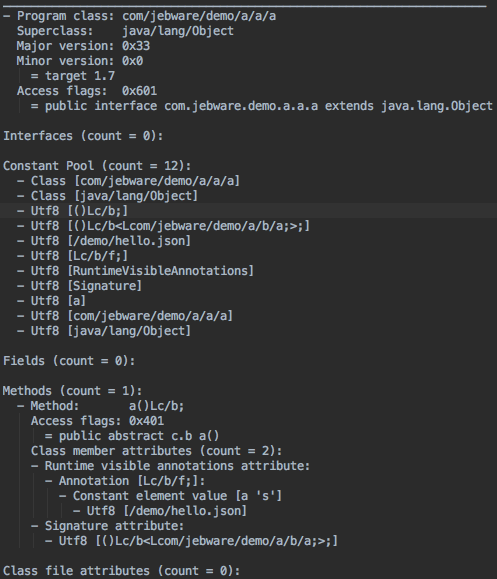
This can be really useful, though, if you want to see what’s in your class files but don’t want to decompile the .class or .dex files.
One last note is that these files are important artifacts of your build — especially mapping.txt. If this is a build you’re going to distribute (say on the Play Store, or even internally for testing), you’re going to need your mapping.txt to de-obfuscate stacktraces.
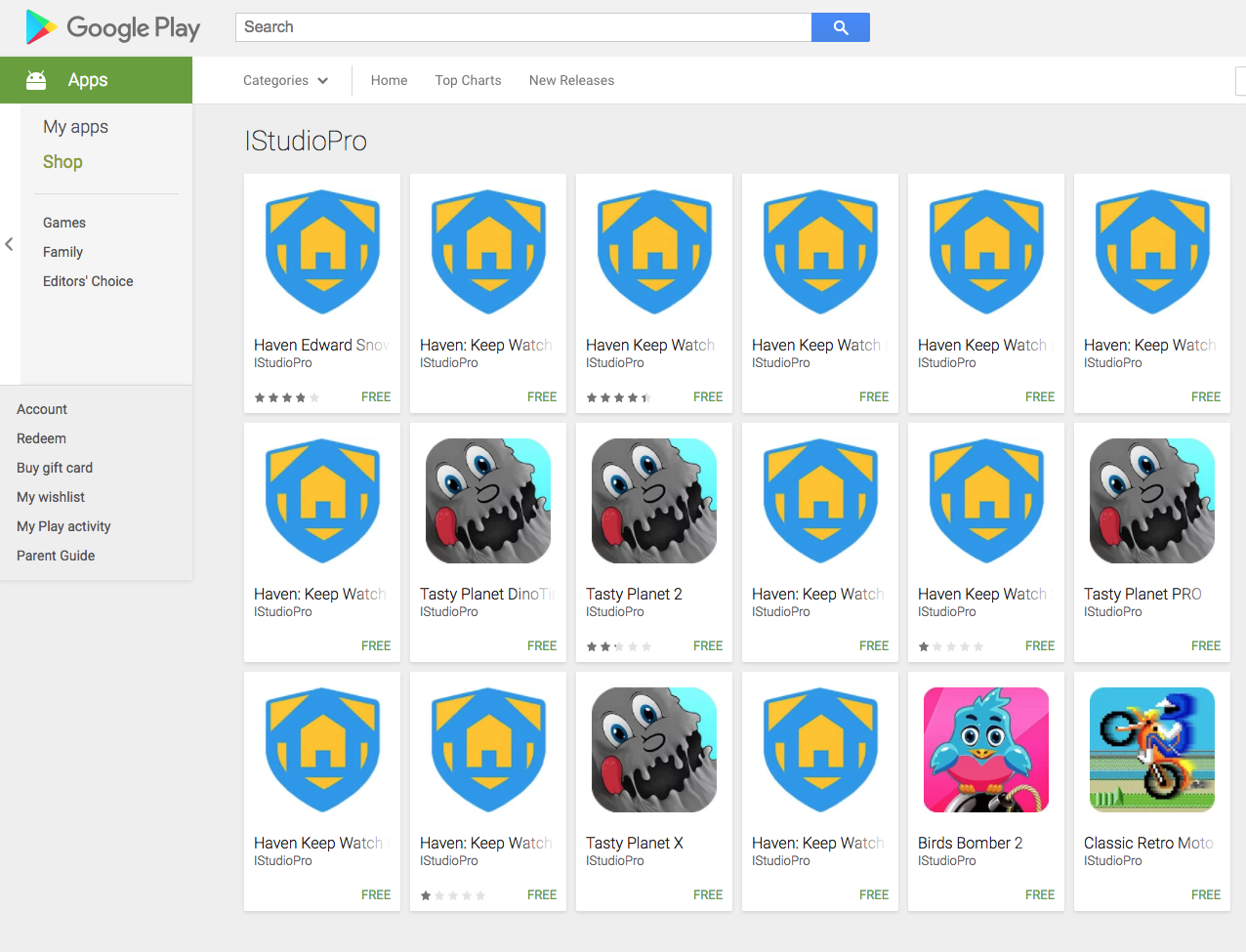
As happens with successful and interesting apps, somebody made impostor copies of the Guardian Project’s Haven app, which got a lot of press due in part to Edward Snowden’s involvement. As of this writing, the copycat has a dozen listings on the Play Store, all with little variations in the name. (Hat tip to @rettiwtkrow, whose tweet was the first I saw of it).
Interestingly, the fake apps have a slightly different icon from the real app. Below is the real app’s icon on the left, and the fake app on the right.
![]() I downloaded half a dozen of these copycats and started reverse-engineering them. The copycats are all the same as each other, only the package name changes. But they’re all completely different from the real app. I wondered at first if they might have ripped off the real app’s code since it’s open source, but no.
I downloaded half a dozen of these copycats and started reverse-engineering them. The copycats are all the same as each other, only the package name changes. But they’re all completely different from the real app. I wondered at first if they might have ripped off the real app’s code since it’s open source, but no.
When you open the fake, it’s immediately clear that they’re just using the name to drive downloads, and the functionality of the app isn’t even trying to look real. It’s a run-of-the-mill crapware “cleaner” app.
It has a tab bar across the bottom, and each tab is a different tool: “Charge Booster”, “Battery Saver”, “CPU Cooler”, and “Junk Cleaner”. They show some made-up stats about the device, and make promises they can’t deliver. For the most part, as you run one of these tools, it displays an animation (that isn’t actually tied to any real work being done), and then a full-screen ad. After one tool, I was presented with a fake Facebook sign-up page.

If you try to apply the “Ultra Power Saving Mode” it sends you to the OS settings app to enable “Allow modify system settings”. I found this alarming, and assumed this is where I would find the nefarious code. So I decompiled the app and poked around, and was honestly pretty underwhelmed.
I should note that the impostor app’s targetSdk is 24, meaning it has to ask for permissions at runtime, which is nice and a little surprising, given that Google isn’t yet forcing developers to do so.
Anyway, I need not have worried – after you grant this app the ability to modify system settings, all it does is turn down your screen brightness, disable autorotation, and disable background syncing for other apps.

(such battery savings. many mAh. very wow)
 Then I got a little worried again when I saw the app has a BroadcastReceiver that runs immediately when the app is installed or updated. This means the app has code that runs in the background even if you never open the app. But again, I shouldn’t have worried because all it does is try to show a toast message saying “[app] Is Optimized by Fast Cleaner & Battery Saver.”
Then I got a little worried again when I saw the app has a BroadcastReceiver that runs immediately when the app is installed or updated. This means the app has code that runs in the background even if you never open the app. But again, I shouldn’t have worried because all it does is try to show a toast message saying “[app] Is Optimized by Fast Cleaner & Battery Saver.”
The bottom line is that these copycats appear to be using the Haven name and publicity just to drive downloads, then make a quick buck off of advertising. I couldn’t find any evidence of anything more sinister than that.
For my last point, let’s talk about attribution. I can’t say for sure, but I have an educated guess where this came from. There’s an app which is almost entirely the same code on the Google Play store. Unlike the Haven copycats, this app has accurate screenshots on the Play Store, and the UI matches the Haven impostors. Either this is the same developer, or it’s a false flag. I can’t rule that out, so I’m not saying this with 100% confidence, but a preponderance of the evidence surely doesn’t look good for that developer.

I assume Google will be along shortly to remove the offending copycats (and hopefully terminate their ad accounts, and the rest of their apps under both publisher listings). But it’s an important reminder that copycats exist, and it’s important to remain vigilant.
The Android Developers website has a chart showing how many Android devices are on each version of the OS. You’ve probably seen it before.
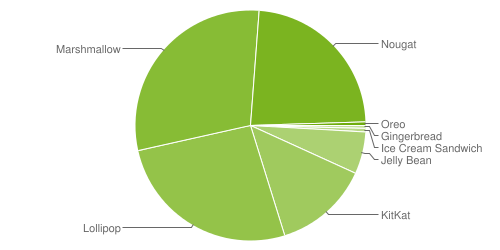
Each month that chart is updated, and Android-focused blogs expend a lot of words analyzing the changes. [1 2 3] Broader tech blogs use it to decry Android’s “fragmentation” problem. [1 2 3 4 5]
But I’m here to let you in on a little secret: that chart doesn’t mean what you think it means, and it’s not all that useful. That chart represents all Android devices, all over the world, that have connected to the Google Play Store in the last seven days.
To show why that group of devices isn’t the data we want, let’s compare that to data from one of my personal apps. And because I’m a nice person, I’m not going to subject you to another pie chart.
For any Android version on the x-axis, the height represents the proportion of devices that are running that version or newer. These are the numbers you need to make the important decision of “what is the lowest version of Android that I’m going to support?” For one example, let’s look at Android 7.0. The Google Play numbers would tell you that only 23.8% of devices are on Android 7.0 or newer, but for my app, that’s 67.8% — a difference of 44%. That’s a night and day difference.
There are a lot of reasons that it’s different, but I’ll cover a few:
If you’re trying to figure out what’s the lowest version of Android that you’re going to support for an existing app, make sure you’re looking at data from your app. I guarantee you it’s going to be different than the public Google Play numbers. And if you’re starting a new app, try to find a source of data that more closely matches your target market.
I think it’s important for any app that deals with sensitive user data to incorporate code obfuscation into their security. While far from impenetrable, it’s a useful layer in thwarting reverse-engineers from understanding your app and using that knowledge against you. If you’ve wondered why I seem to be on a code obfuscation kick recently, it’s because I’ve noticed, anecdotally, that a lot of apps I expected to be using obfuscation, weren’t. So I set out to see if I could do some research and turn that anecdote into data.
I took all of the apps I have on my phone right now, and calculated how well the code was obfuscated (see methodology notes at the end of the post if you’re curious). Here are the points that jumped out at me:
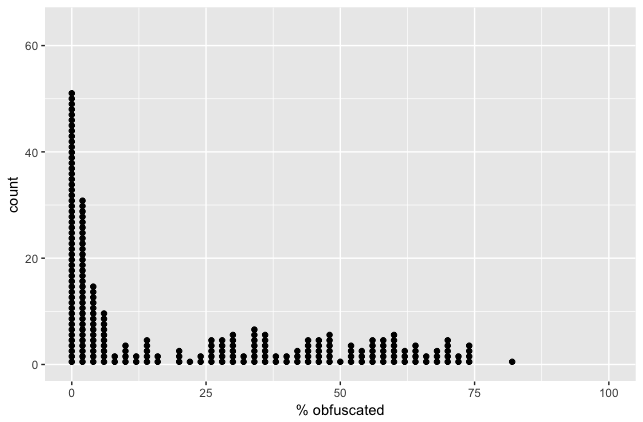
Why would an app with ProGuard turned off have a score greater than 0? A small part of that would be due to false positives (see the “Methodology” section, below) but most is due to third-party library code that has its internal implementation details obfuscated, before that code is even packaged into an app.
I like to organize my ProGuard rules by breaking them up into separate files, grouped by what they’re acting on — my data model, third-party libs, etc.

It’s tempting to reference one main ProGuard file from your build.gradle, and then put ‘-include’ entries in the main file to point to the rest, but there’s a problem with this. If you make a change in one of the included files, it won’t be picked up until you do a clean build.
The reason for this is Gradle’s model of inputs and outputs for tasks. Gradle is really smart about avoiding unnecessary work, so if none of the inputs for a task have changed, then Gradle won’t rerun the task. If you list one main ProGuard file in your build.gradle and include the rest from there, Gradle only sees the main file as an input. So if you make changes in an included file, Gradle doesn’t think anything changed.
The easy way I’ve found to work around this is to put all of my ProGuard rules into a directory, and include them all in your build.gradle with this snippet:
If you search for ProGuard rules for a Java or Android library, you’ll see a lot of answers on StackOverflow that tell you to do something like this:
-keep class com.foo.library.** { *; }
That advice is really bad, and you should never do it. First, it’s overly broad — that double-asterisk in the package means every class under every package under that top-level package; and the asterisk inside the curly braces applies to every member (variables, methods, and constants) inside those class. That is, it applies to all code in the library. If you use that rule, Jake Wharton is going to come yell at you:
Second, and what this post is about, is the beginning of the directive, that “-keep”. You almost never want to use -keep; if you do need a ProGuard rule, you usually want one of the more specific variants below. But it always takes me a minute with the ProGuard manual to figure out which one of those variants applies to my case, so I made some tables for quick visual reference. (Quick aside: the ProGuard manual is very useful and I highly recommend you look through it.)
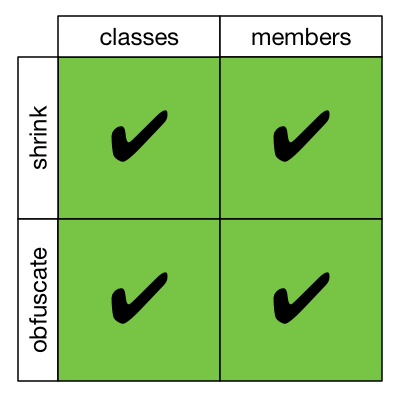
To get our bearings, let’s look at the default. If you don’t specify a keep directive of any kind, then ProGuard is going to do it’s normal thing — it’s going to both shrink (i.e. remove unused code) and obfuscate (i.e. rename things) both classes and class members.
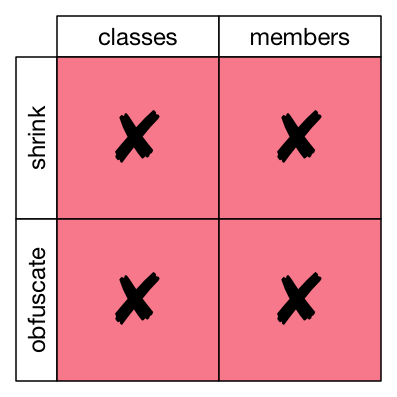
See, this is why I said you should almost never use -keep. -keep disables all of ProGuard’s goodness. No shrinking, no obfuscation; not for classes, not for members. In real use cases, you can let ProGuard do at least some of it’s work. Even if your variables are accessed by reflection, you could remove and rename unused classes, for example. So let’s look through the more specific -keep variants.
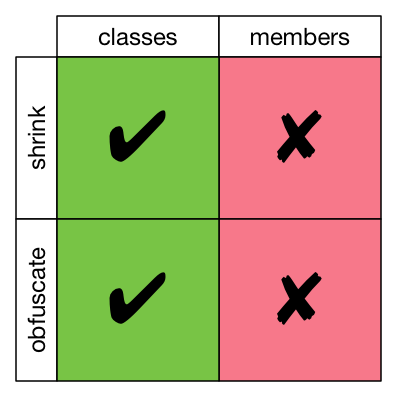
This protects only the members of the class from shrinking and obfuscation. That is, if a class is unused, it will be removed. If the class is used, the class will be kept but renamed. But inside any class that is kept around, all of its members will be there, and they will have their original names.
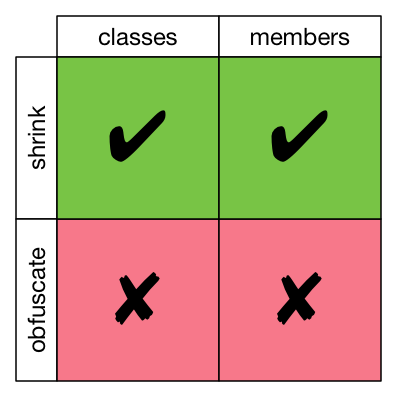
This allows shrinking for classes and members, but not obfuscation. That is, any unused code is going to get removed. But the code that is kept will keep its original names.
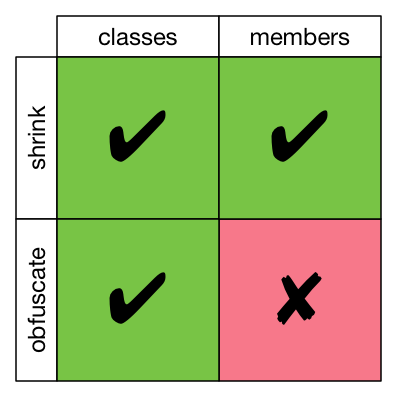
This is the most permissive keep directive; it lets ProGuard do almost all of its work. Unused classes are removed, the remaining classes are renamed, unused members of those classes are removed, but then the remaining members keep their original names.
This one doesn’t get a table, because it’s the same as -keep. The difference is that it only applies to classes who have all of the members in the class specification.
Similarly, this rule is the same as -keepnames. The difference, again, is that it only applies to classes who have all of the members in the class specification.
You want to let ProGuard do as much work as possible, so pick the directive that has the fewest red X blocks above, while still meeting your need.

